语言模型可以生成连贯且语法正确的文本,但它们并不能甄别虚假信息。
谷歌为了应对ChatGPT而自信推出的Bard,迅速被指出犯了低级错误,这暴露了类似的人工智能系统实际上并不具备“理解能力”。
华尔街见闻稍早时候曾介绍,有专家指出Bard在该产品的第一个演示视频中犯了一个“事实错误”。
在视频中,Bard回答了一个关于通过詹姆斯韦伯太空望远镜获得的新发现的问题,称它“拍摄了我们太阳系外行星的第一张照片”。然而天文学家们指出,第一张系外行星照片是由欧洲南方天文台的甚大望远镜(VLT)在2004年拍摄的。
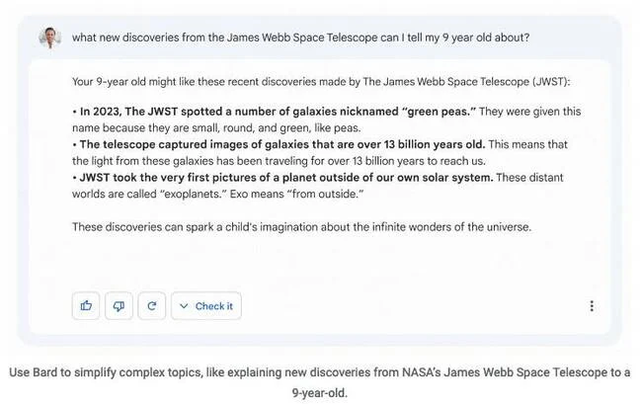
天文学家们认为,这一问题可能源于人工智能误解了“模棱两可的NASA新闻稿,低估了过去的历史”。
这个故障凸显了Bard等所谓的生成人工智能系统的一个常见缺陷:这些系统不能“理解”它们反刍的信息,只能根据概率进行猜测。而微软也承认了它的聊天机器人也面临类似的挑战。
尽管语言模型可以生成连贯且语法正确的文本,但它们也会表达虚假信息。
离奇的是,上述错误通过了谷歌的各个工程、法律、公关和营销部门,并在出现在了Bard最重要的演示中。
Bard的“出师不利”,无疑对本就急需这一战“扳回一城”的谷歌造成打击。周三,谷歌一度跌去近10%市值,损失高达1200亿美元。
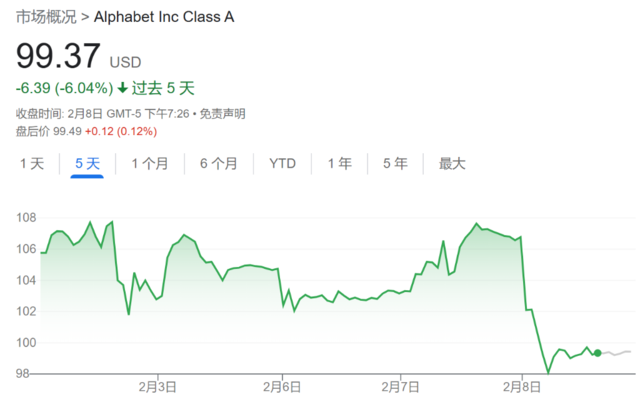
除此之外,谷歌的利润下降可能也在所难免。去年四季度,谷歌营收和EPS均逊于预期,连续第三个季度盈利同比下滑,广告收入下降了4%,是其历史上第二个季度萎缩。
行动太仓促
Bard出现重大错误,可能反映出谷歌为了应对微软,在推行这一项目时过于匆忙。
有媒体指出,ChatGPT在去年推出时,也被人们发现了会提供错误信息。尽管OpenAI没有提供错误信息频率的统计数据,但这家公司表示,会通过定期更新使该工具变得更好。
相比之下,谷歌似乎在使用这项新技术方面更加大胆。
在微软发布的必应的例子中,聊天机器人的答案将被降级到页面的一侧,而不是通常搜索结果将保留的前面和中心。机器人的回答还包括脚注和来源材料的链接,这在ChatGPT当中是没有的,但这使得微软的工具看起来更值得信赖。
反观谷歌的Bard,回答放在页面中间、搜索结果上方显示了单一的摘要答案,并且没有脚注,这意味着用户不可能识别来源。
这也许是因为谷歌面临着迅速行动的压力。
OpenAI等公司试图通过增加数十亿个参数来提高语言模型的准确性,但一些研究人员怀疑,随着模型的增长,准确性的回报会递减。
对微软和谷歌来说,消除这些持续存在的少数谎言可能成为一项长期挑战。
")
")

{kind=link}