{kind=link}
我的一些网站正在被你的用户攻击,你不能不经同意就抓取我的照片信息。

Eden

Romain
你要是不想让人看你发网上的照片,你就把它删除啊。
这段对话来自图片抓取工具 Img2dataset 的 GitHub 页面,争论的双方,是被抓取图片的网站站长Eden,和抓取工具的开发者 Romain。

▲
双方发言的赞踩数,似乎能看到大众的偏向
发布上网 = 默认同意 AI 训练
不论是 Open AI 的 DALL-E、Google 的 Imagen,还是开源的 StableDiffusion,任何由文字生成图片的通用大模型,都需要经过大量的数据训练,网络是训练信息的最佳来源。
Eden 建立了一个名为 OpenBenches的网站,邀请用户上传世界各地的纪念长椅图片和位置。截至今日,OpenBenches 已经收集了超过两万七千张长椅,托管了 250GB的照片。

一日,Eden 收到了服务器报警,说网站正在受到持续攻击,来源正是上文中提到的 Img2dataset。原因很简单,有人把Eden 网站里的长椅图片用于了 AI 训练。
因为网站流量的激增,导致 Eden 不仅支付了额外费用,还花费了不少时间去阻止抓取工具的滥用。
当然,Img2dataset 的抓取并不是无法禁止的,只需为网站加入「X-Robots-Tag: NoAI」的标头,就可以避免被Img2dataset 抓取,如果你没有加,则默认你同意自己的网站数据可以被用于 AI训练。这就出现了争论的关键:作为所有者,我应该选择加入,而不是选择退出。

▲
「你剥夺了人们的同意权」
听起来似乎有一点绕,举一个不太恰当的例子,我在手机上下载了一款新app,在没有打开前,它就已经获取了所有权限,并根据信息推送了广告通知,当我质问开发者时,却得到了「你要是不想看广告,就不要用手机啊」的回复。
怎么样,你开始生气了吗?
公司能收费,个人没办法
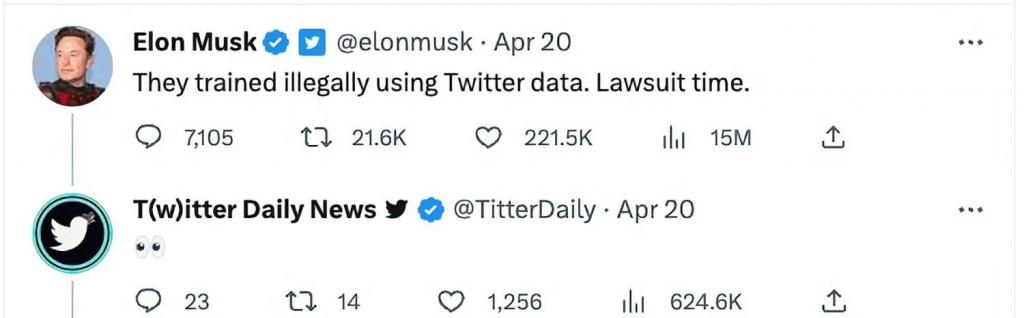
今年 2 月,Twitter 宣布不再支持免费 API 访问,如果你想访问 Twitter 的数据,需要每月支付 4.2 万到21 万美元不等的费用,金额越高,研究人员或企业获得的推文数量就越多。
因此,微软则宣布数字营销中心(DMC)随后表示不再支持Twitter,这将导致用户不能再通过微软的免费社交媒体管理服务创建、管理他们的推文。
Twitter CEO 马斯克也一点都不含糊:微软在用 Twitter 的数据进行非法训练,接下来是诉讼时间。
知名社交媒体 Reddit 拥有庞大的用户群体和活跃的社交板块,同时不少板块的内容也相当专业权威,这让它成为了一个非常好的 AI学习资料库。
Google Bard 和 ChatGPT 都曾引用 Reddit 的数据做其训练的信息来源之一。

▲
两者的语义学习文档中都出现过 Reddit 的身影
「Reddit 的数据语料库非常有价值,我不能免费将这些价值提供给世界级大公司。」Reddit 创始人 Steve在采访中表示。
上周二,Reddit 追随 Twitter 的脚步,开始向大公司收取 API 访问费用。
你构建未来与我竞争的工具,而我还要把数据免费提供给你,怎么想都不合理。

对大公司来说,改变 API 的开放策略尚是一件需要进行多方权衡的反击方法,而像 Eden 这样的个人网站运营者或者普通网友,面对AI 默认同意的照片训练,并没有太好的应对方法。
音乐家 Holly Herndon 创建了一个名为「Have I Been Trained」的网站,收集了 5 亿张用于 AI艺术模型训练的图片,旨在帮助艺术家了解他们的作品是否包含在 AI 模型训练的数据集中。
我尝试在网站中搜索了「Jay Chou」,不知这些被用来进行 AI 训练的周杰伦照片,有没有经过周董本人的同意。

▲
网站:https://haveibeentrained.com/
那么,我可以不让 AI 识别我的照片吗?当然可以,那就是 Img2dataset 开发者提供的方法了:拒绝 AI识别的最佳方法,就是删除它——不想让我用?那你就别上传。
人工智能正在以惊人的速度发展,AI工具方便了我们的工作生活,但我们似乎还没有想好,该如何应对为人工智能提供动力的数据源。
请给我们「同意」的权利
在「长椅」网站所有者 Eden 与图片采集工具开发者 Rom 的争论中,后者提到一个观点:被 Google搜索是搜,被我搜索也是搜,为什么你愿意让 Google 收录你的网站,不允许我搜索呢?

这看起来似乎有些道理,但 Google 搜索中心为开发者提供了一个非常全面的防请求机制:robots.txt。
使用这个文件,就可以避免网站收到过多的请求,它并不是一种阻止 Google抓取某个网页的机制,而是为了更加合理的分配流量。

有网友指出,Img2dataset 主动忽略了 robots.txt,这个做法显然是恶意的。而且,相比全球最大的搜索引擎Google,Img2dataset 这样的小工具数量更多、迭代更快,今天禁止了这个,明天就会冒出那个。
「难道每出现一个新工具,我就要选择一次拒绝?」Eden 提出的疑问,也是我们每个人可能会遇到的事。
或许是为了利益,或许是寻求方便,不管是故意的还是不小心,「默认同意」似乎成为了 AI高速发展的秘密武器。但我始终认为,同意是道德的基石,AI 发展的同时,也需要更加合理的数据集采集方式。
在争辩的最后,Rom 依然坚持自己的观点:很遗憾,你们中的一些人还是不理解 AI的潜力,作为创作者,你们有更多机会从中受益,却与此斗争,这令人感到悲哀。
<
p style=”text-align:center;”>
AI 在飞速发展,而要走的路还是很长。